A Real-Time Flash Translation Layer for NAND Flash Memory Storage Systems
IEEE TRANSACTIONS ON MULTI-SCALE COMPUTING SYSTEMS 2016
이 논문에서 주장하는 contribution
1.real-time address mapping
2.distributed partial garbage collection
3.real-time scheduler
비교대상FTL
GFTL [2], RTGC [3], Pure-Block-Level FTL [4]
([No.]는 references를 말함)
내용 정리
real time task T={p, e, d}
p = period
e = execution time
d = deadline
예: read T_r = {p_r, e_r, d_r}, write T_w = {p_w, e_w, d_w}
p_r, p_w
denote the frequency of a read or write request arriving from the file system.
e_r
time taken to search for a target page
e_w
time overhead to search for a free page
The first write to the LBN is written to the first free page of the primary block, and the
pages in the primary block are allocated sequentially from page 0.
sub-table and the data are written to the OOB area and data area, respectively. A page table index is stored in RAM to keep track of the mapping information
정리사항
([No.]는 references를 말함)
내용 정리
real time task T={p, e, d}
p = period
e = execution time
d = deadline
예: read T_r = {p_r, e_r, d_r}, write T_w = {p_w, e_w, d_w}
p_r, p_w
denote the frequency of a read or write request arriving from the file system.
e_r
time taken to search for a target page
e_w
time overhead to search for a free page
1.real-time address mapping
hybrid-level address mapping 방식을 사용한다.
따라서, block level mapping과 page level mapping 두 가지 역할이 나온다.
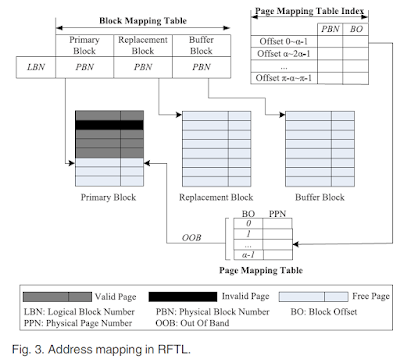
Block level mapping은 logical block을 3개의 physical block에 map하는 역할을 한다.
여기서 제시한 architecture에서는 3개의 physical block을 사용한다.
primary block, replacement block, buffer block
역할: The primary block is first used to serve the write requests, and the buffer block will serve the pending write requests when the primary block is full, while the replacement block provides a space to reclaim the primary block. These three blocks can periodically change their functions to provide guaranteed space for write operations.
Page level mapping table은 logical page와 physical page 사이의 주소 mapping을 위해 사용이 된다. table은 RAM cost를 줄이기 위해 N개( N=[π/α] )의 작은 table로 나뉘어, 새롭게 할당된 page의 OOB에 저장하게 된다. logical block과 physical block이 π개의 page를 가지고 있다고 가정하고, 하나의 logical block에 대한 page level mapping table은 π개의 entries를 가지게 된다. 이때, 하나의 physical page가 α (π≥α>0)개의 mapping slots의 entries가 저장 가능하다. 이렇게 N 개의 sub-table로 나눠진것들에 대해 N page address mapping table indices들을 RAM에 기록한다.
hybrid-level address mapping 방식을 사용한다.
따라서, block level mapping과 page level mapping 두 가지 역할이 나온다.
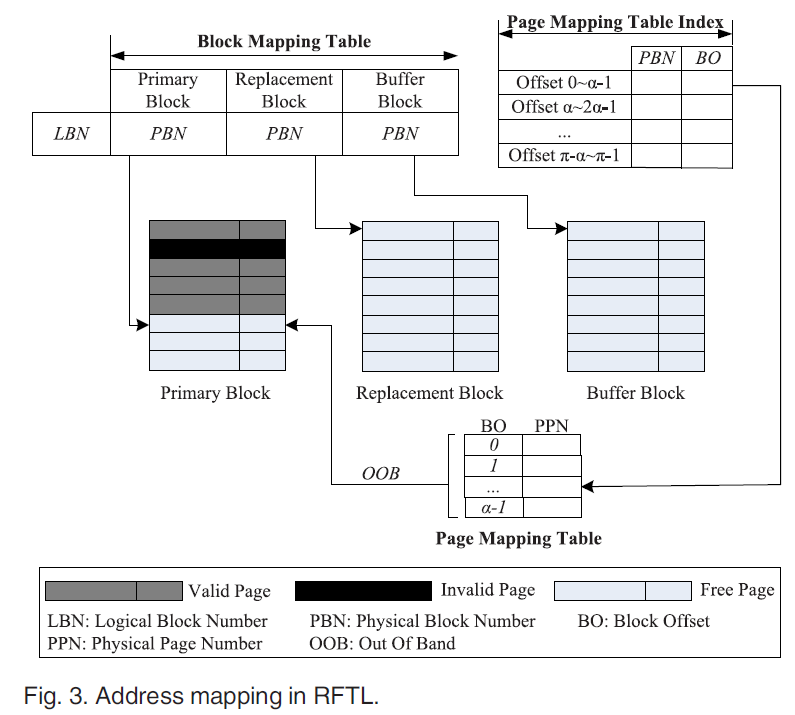
여기서 제시한 architecture에서는 3개의 physical block을 사용한다.
primary block, replacement block, buffer block
역할: The primary block is first used to serve the write requests, and the buffer block will serve the pending write requests when the primary block is full, while the replacement block provides a space to reclaim the primary block. These three blocks can periodically change their functions to provide guaranteed space for write operations.
Page level mapping table은 logical page와 physical page 사이의 주소 mapping을 위해 사용이 된다. table은 RAM cost를 줄이기 위해 N개( N=[π/α] )의 작은 table로 나뉘어, 새롭게 할당된 page의 OOB에 저장하게 된다. logical block과 physical block이 π개의 page를 가지고 있다고 가정하고, 하나의 logical block에 대한 page level mapping table은 π개의 entries를 가지게 된다. 이때, 하나의 physical page가 α (π≥α>0)개의 mapping slots의 entries가 저장 가능하다. 이렇게 N 개의 sub-table로 나눠진것들에 대해 N page address mapping table indices들을 RAM에 기록한다.
2.distributed partial garbage collection
distributed partial GC를 사용해서 RFTL로 하여금 공간회수와 write request들을 동시에 제공할 수 있게한다. RFTL에서 GC는 primary block이 가득차고 write request가 primary block에 issue될때 동작하게 된다. GC 또는 valid page copy동작은 p 주기 안에서 write혹은 read가 끝나고 남은 t시간에 대해서 발생하게 된다.


위의 알고리즘 동작을 함에 있어 세개의 physical block은 worst cast response time의 boundary내에서 guarantee가 필요하다.
동작: When the primary block is full and garbage collection operation is triggered, write request will be serviced in the first page of the buffer block. Meanwhile, valid pages in the primary block are copied to the replacement block. After the primary block is reclaimed, an exchange operation is performed to change the position of the primary
block and the replacement block. When the buffer block has only x free pages left, the partial garbage collection of the primary block is triggered again. The replacement block will store the valid pages from both the primary block and the buffer block.
distributed partial GC를 사용해서 RFTL로 하여금 공간회수와 write request들을 동시에 제공할 수 있게한다. RFTL에서 GC는 primary block이 가득차고 write request가 primary block에 issue될때 동작하게 된다. GC 또는 valid page copy동작은 p 주기 안에서 write혹은 read가 끝나고 남은 t시간에 대해서 발생하게 된다.


동작: When the primary block is full and garbage collection operation is triggered, write request will be serviced in the first page of the buffer block. Meanwhile, valid pages in the primary block are copied to the replacement block. After the primary block is reclaimed, an exchange operation is performed to change the position of the primary
block and the replacement block. When the buffer block has only x free pages left, the partial garbage collection of the primary block is triggered again. The replacement block will store the valid pages from both the primary block and the buffer block.
3.real-time scheduler
If no garbage collection is involved, RFTL will only execute this request in one period p. Otherwise, if the primary block is full and the garbage collection is invoked, the valid-page copy operations and the erase operation performed on the garbage collection are divided into partial steps, and the time taken to perform each step is no longer than the longest atomic operation in flash (that is the block erase operation T_er).The first write to the LBN is written to the first free page of the primary block, and the
pages in the primary block are allocated sequentially from page 0.
sub-table and the data are written to the OOB area and data area, respectively. A page table index is stored in RAM to keep track of the mapping information
정리사항
궁금한점
1. A novel hybrid-level address mapping approach is designed to provide sufficient free space to serve the pending write operations.
→ hybrid mapping 방식은 기본적으로 block mapping을 사용하고, log block에 한해서 page mapping table을 유지하므로 page level mapping 방식과 비교해 RAM 사용 공간에 있어서 이득이 있다. 그리고 log block이 존재하므로, que에 쌓여 있는 pending write operation에게 free space를 제공할 수 있다.
→ hybrid mapping 방식은 기본적으로 block mapping을 사용하고, log block에 한해서 page mapping table을 유지하므로 page level mapping 방식과 비교해 RAM 사용 공간에 있어서 이득이 있다. 그리고 log block이 존재하므로, que에 쌓여 있는 pending write operation에게 free space를 제공할 수 있다.
참고:http://ji007.tistory.com/entry/FTL-address-mapping
→ 이 논문에서는 위 사이트에 나와 있는 방식과는 다르다. 여기서 hybrid mapping이라는것은 block level mapping과 page level mapping을 사용했다. 이것이다. 실제로 사용하는 방식은 달라서 novel이라고 붙였다.
→ 이 논문에서는 위 사이트에 나와 있는 방식과는 다르다. 여기서 hybrid mapping이라는것은 block level mapping과 page level mapping을 사용했다. 이것이다. 실제로 사용하는 방식은 달라서 novel이라고 붙였다.
2.distributed partial garbage collection policy is proposed to reduce the worst-case block time for each write operation
->distributed의 의미가 무엇일까? partial의 의미가 무엇일까? 어떻게 이것들을 적용했기에 write operation에 있어서 response time이 줄어들었을까
->이 논문에서 distributed의 의미는 GC의 동작이 data copy와 erase로 구성되어 있으며, 이 둘의 동작을 request들 사이의 idle time때 분산시켜서 GC동작을 하겠다는 의미이다. partial은 partial merge를 말한다.
참고:http://ji007.tistory.com/entry/FTL-Design-based-on-Log-Blocks
write operation시 GC동작이 수반되므로, variable response time으로 real time에 있어 충족이 되지 못한다. 따라서, GC overhead가 줄어들어 response time을 줄여준다.
참고:http://ji007.tistory.com/entry/FTL-Design-based-on-Log-Blocks
write operation시 GC동작이 수반되므로, variable response time으로 real time에 있어 충족이 되지 못한다. 따라서, GC overhead가 줄어들어 response time을 줄여준다.
3.upper bound, lower bound의 의미
->lower bound on p (denoted as L(p)) gives the maximum request arrival rate that an FTL can handle. 이 말은 "request들간의 주기가 짧아 그만큼 많은 request들이 FTL을 통해 처리 될 수 있다."라고 의미가 해석된다.
->upper bound on e (denoted as U(e)) shows the worst-case execution time for requests when no garbage collection in involved. 이 말은 "상한선의 실행시간을 가지기 때문에 worst case로 본다."고 의미가 해석된다.
->upper bound on e (denoted as U(e)) shows the worst-case execution time for requests when no garbage collection in involved. 이 말은 "상한선의 실행시간을 가지기 때문에 worst case로 본다."고 의미가 해석된다.
4.Without loss of generality, we assume that p is equal to d.
->p와 d가 왜 같을까
5.From the perspective of the file system, L(p) represents the worst-case response time when garbage collection is considered
->lower bound로 request들이 계속적으로 오게되는데 Garbage collection이 일어나게 되면, 해당 request들은 pending 상태가 되므로, worst case response time으로 고려된다.
->p와 d가 왜 같을까
5.From the perspective of the file system, L(p) represents the worst-case response time when garbage collection is considered
->lower bound로 request들이 계속적으로 오게되는데 Garbage collection이 일어나게 되면, 해당 request들은 pending 상태가 되므로, worst case response time으로 고려된다.
6.3개의 physical block을 사용하는데 그렇다면, 제공하는 용량에 비해서 실제로 사용 하는 용량이 줄어들게 되는것인가?
7.These three blocks can periodically change their functions to provide guaranteed space for write operations.
->왜 3개의 block들은 주기적으로 역할이 바뀌는 것일까? 그렇다면, 어떠한 조건하에 바뀌게 되는것일까?
8.A page-level mapping table is used to maintain the address mapping between a logical page and a physical page
->hybrid level mapping에서 사용되는 page level mapping은 log block을 위해 사용이 되는데 그것을 말하는 것일까?->그건 아닌거 같다. Each physical page may belong to primary block, replacement block, or buffer block. 세가지에 모두 속할 수 있다.
->그렇다면, 기존의 hybrid mapping에서는 page level mapping을 log block을 위해서 사용을 했는데, 여기서는 단순히 각 logical block에 대한 모든 page들에 대해서 physical page가 어디에 있는지 나타내는것인가?그렇다면 모든 logical page가 다 포함이 되는것 아닌가??
->아니다. block mapping table을 통해서 block을 접근해서 사용하고, log block을 위한 page mapping table처럼 사용된다. 단순히 physical page offset이 primary, replacement, buffer중 하나가 될 수 있다는 것이다.
->hybrid level mapping에서 사용되는 page level mapping은 log block을 위해 사용이 되는데 그것을 말하는 것일까?->그건 아닌거 같다. Each physical page may belong to primary block, replacement block, or buffer block. 세가지에 모두 속할 수 있다.
->그렇다면, 기존의 hybrid mapping에서는 page level mapping을 log block을 위해서 사용을 했는데, 여기서는 단순히 각 logical block에 대한 모든 page들에 대해서 physical page가 어디에 있는지 나타내는것인가?그렇다면 모든 logical page가 다 포함이 되는것 아닌가??
->아니다. block mapping table을 통해서 block을 접근해서 사용하고, log block을 위한 page mapping table처럼 사용된다. 단순히 physical page offset이 primary, replacement, buffer중 하나가 될 수 있다는 것이다.
9.In order to reduce the RAM cost, the page-level mapping table is divided into N
small tables
->page level mapping 방식으로 table을 구성 했을때 대비, 얼만큼 정도의 RAM cost 이득이 있는지, 그리고 N개로 왜 나눠야 하는지? N개로 나누면 그만큼 덜 불러서 RAM에 올린다는 것인가?
10.the buffer block will serve the pending write requests when the primary block is full
->primary block이 가득차지 않으면, buffer block은 write 될수 없는것인가??3가지 physical block들의 상관관계에 대해 정리가 필요하다.
11.block mapping table에 PBN부분에 대해서 3가지 physical block의 정보가 있는데 이로 인해서 증가된 bit로 table의 사이즈가 많이 커지는거는 아닌지?
12. 원래 size가 조금 크더라도 address mapping table을 한 번 읽으면 해당 block 혹은 page를 찾아가서 실행할 수 있는것 아닌가? 지금처럼 page mapping table index를 이용 한 접근을 하게 되면, RAM에서 index 한번 읽고 OOB접근해서 다시 읽는 과정을 거칠텐데, overhead로 작용하지 않을까?
13.GC할때 read후 write를 할텐데, 이때 바로 page에 옮기나?아니면 중간 buffer를 거친 후 옮길까?
14.GC의 동작을 보면 primary block이 가득찬 상태에서 다시 write가 발생했을때, buffer block으로 write를 하고 valid page copy와 GC 동작을 한다고 나와 있는데, 나는 hybrid mapping 방식을 사용 했다고 해서, buffer block이 log block으로 사용되는줄 알았는데 그게 아니라 primary block에 sequential하게 저장되는 형태인것처럼 보인다.
15.buffer block에서 x page가 남게 되면, primary bock의 partial GC가 일어나 replacement block에 primary block과 buffer block의 valid page들을 모아서 저장할텐데, 왜 buffer block이 full이 되는 상황이 발생할 수 있는거지?
->일어 날수 있는 상황임. primary block이 full로 가득차면 지속적으로 들어오는 write request들은 buffer block으로 들어가고 x page 이상에서는 primary block만 GC가 일어나기 때문에, buffer block은 계속적으로 누적된다. 그러다가 x page 이하로 남게 되면 그때 buffer block과 primary block 둘다 partial GC를 하게 된다.
->그런데 worst case로 primary block의 valid page와 buffer block의 valid page의 개수 합이 replacement block의 총 page 개수보다 많아 지는 상황에서는 어떻게 처리가 되지?
16.알고리즘3.1에서 issue initial write request한 뒤 issue update request to RBlk를 하는데 왜 replacement block에 request를 하는지
17.여기서는 block level mapping을 했다고 하지만, GC함에 있어서 input으로 들어오는 write request들이 동일한 주소를 접근하는것에 대한 언급은 없다. 그 부분에 대해서 고민을 해야한다. 동일 주소로 접근시 어떻게 처리할지에 대해서
18.t ≥ Te인 경우에 대해서만 GC가 가능하다고 얘기를 하는데, 그렇다면, 반대의 경우에는 idle time에 아무것도 할 수 없는건가?
19.Since three physical blocks are mapped to the logical block with LBN, the first write to the LBN is written to the first free page of the primary block, and the pages in the primary block are allocated sequentially from page 0.
->LPB을 LBN+BO로 변환후 LBN만 사용하고, log block처럼 순차적으로 그냥 내용 저장하는것인가?
20.on mapping slot(BO,PBN) is formed.
->전체 데이터에 대한 모든것들을 다 mapping slot에 유지해야 하니까 사이즈가 커야 하는거 아닌가??
small tables
->page level mapping 방식으로 table을 구성 했을때 대비, 얼만큼 정도의 RAM cost 이득이 있는지, 그리고 N개로 왜 나눠야 하는지? N개로 나누면 그만큼 덜 불러서 RAM에 올린다는 것인가?
10.the buffer block will serve the pending write requests when the primary block is full
->primary block이 가득차지 않으면, buffer block은 write 될수 없는것인가??3가지 physical block들의 상관관계에 대해 정리가 필요하다.
11.block mapping table에 PBN부분에 대해서 3가지 physical block의 정보가 있는데 이로 인해서 증가된 bit로 table의 사이즈가 많이 커지는거는 아닌지?
12. 원래 size가 조금 크더라도 address mapping table을 한 번 읽으면 해당 block 혹은 page를 찾아가서 실행할 수 있는것 아닌가? 지금처럼 page mapping table index를 이용 한 접근을 하게 되면, RAM에서 index 한번 읽고 OOB접근해서 다시 읽는 과정을 거칠텐데, overhead로 작용하지 않을까?
13.GC할때 read후 write를 할텐데, 이때 바로 page에 옮기나?아니면 중간 buffer를 거친 후 옮길까?
14.GC의 동작을 보면 primary block이 가득찬 상태에서 다시 write가 발생했을때, buffer block으로 write를 하고 valid page copy와 GC 동작을 한다고 나와 있는데, 나는 hybrid mapping 방식을 사용 했다고 해서, buffer block이 log block으로 사용되는줄 알았는데 그게 아니라 primary block에 sequential하게 저장되는 형태인것처럼 보인다.
15.buffer block에서 x page가 남게 되면, primary bock의 partial GC가 일어나 replacement block에 primary block과 buffer block의 valid page들을 모아서 저장할텐데, 왜 buffer block이 full이 되는 상황이 발생할 수 있는거지?
->일어 날수 있는 상황임. primary block이 full로 가득차면 지속적으로 들어오는 write request들은 buffer block으로 들어가고 x page 이상에서는 primary block만 GC가 일어나기 때문에, buffer block은 계속적으로 누적된다. 그러다가 x page 이하로 남게 되면 그때 buffer block과 primary block 둘다 partial GC를 하게 된다.
->그런데 worst case로 primary block의 valid page와 buffer block의 valid page의 개수 합이 replacement block의 총 page 개수보다 많아 지는 상황에서는 어떻게 처리가 되지?
16.알고리즘3.1에서 issue initial write request한 뒤 issue update request to RBlk를 하는데 왜 replacement block에 request를 하는지
17.여기서는 block level mapping을 했다고 하지만, GC함에 있어서 input으로 들어오는 write request들이 동일한 주소를 접근하는것에 대한 언급은 없다. 그 부분에 대해서 고민을 해야한다. 동일 주소로 접근시 어떻게 처리할지에 대해서
18.t ≥ Te인 경우에 대해서만 GC가 가능하다고 얘기를 하는데, 그렇다면, 반대의 경우에는 idle time에 아무것도 할 수 없는건가?
19.Since three physical blocks are mapped to the logical block with LBN, the first write to the LBN is written to the first free page of the primary block, and the pages in the primary block are allocated sequentially from page 0.
->LPB을 LBN+BO로 변환후 LBN만 사용하고, log block처럼 순차적으로 그냥 내용 저장하는것인가?
20.on mapping slot(BO,PBN) is formed.
->전체 데이터에 대한 모든것들을 다 mapping slot에 유지해야 하니까 사이즈가 커야 하는거 아닌가??
댓글 없음:
댓글 쓰기